RMA communications fall in two categories:
Distinct access epochs for win at the same process must be disjoint. On the other hand, epochs pertaining to different win arguments may overlap. Local operations or other MPI calls may also occur during an epoch.
In active target communication, a target window can be accessed by RMA operations only within an exposure epoch. Such an epoch is started and completed by RMA synchronization calls executed by the target process. Distinct exposure epochs at a process on the same window must be disjoint, but such an exposure epoch may overlap with exposure epochs on other windows or with access epochs for the same or other win arguments. There is a one-to-one matching between access epochs at origin processes and exposure epochs on target processes: RMA operations issued by an origin process for a target window will access that target window during the same exposure epoch if and only if they were issued during the same access epoch.
In passive target communication the target process does not execute RMA synchronization calls, and there is no concept of an exposure epoch.
MPI provides three synchronization mechanisms:
This call is used for active target communication. An access epoch at an
origin process or an exposure epoch at a target process are started
and completed by calls to MPI_WIN_FENCE. A process can
access windows at all processes in the group of win during
such an access
epoch, and the local window can be accessed by all processes in the
group of win during such an exposure epoch.
2. The four functions MPI_WIN_START,
MPI_WIN_COMPLETE, MPI_WIN_POST and MPI_WIN_WAIT
can be used to restrict synchronization to the minimum: only
pairs of communicating processes synchronize, and they do so only when
a synchronization is needed to order correctly RMA accesses to a
window with respect to local accesses to that same window.
This mechanism may be
more efficient when each process communicates with few (logical)
neighbors, and the communication graph is fixed or changes
infrequently.
These calls are used for
active target communication. An access epoch is started
at the origin process
by a call to MPI_WIN_START and is terminated by a call to
MPI_WIN_COMPLETE. The start call has a group argument
that specifies the group of target processes for that
epoch. An exposure epoch is started at the
target process by a call
to MPI_WIN_POST and is completed by a call to
MPI_WIN_WAIT. The post call has a group argument that
specifies the set of origin processes for that
epoch.
3. Finally,
shared and exclusive locks are provided by the two functions
MPI_WIN_LOCK and MPI_WIN_UNLOCK.
Lock synchronization
is useful for MPI applications that
emulate a shared memory model via MPI calls; e.g., in a ``billboard''
model, where processes can, at random times, access or update
different parts of the billboard.
These two calls provide passive target communication. An access epoch is started by a call to MPI_WIN_LOCK and terminated by a call to MPI_WIN_UNLOCK. Only one target window can be accessed during that epoch with win.
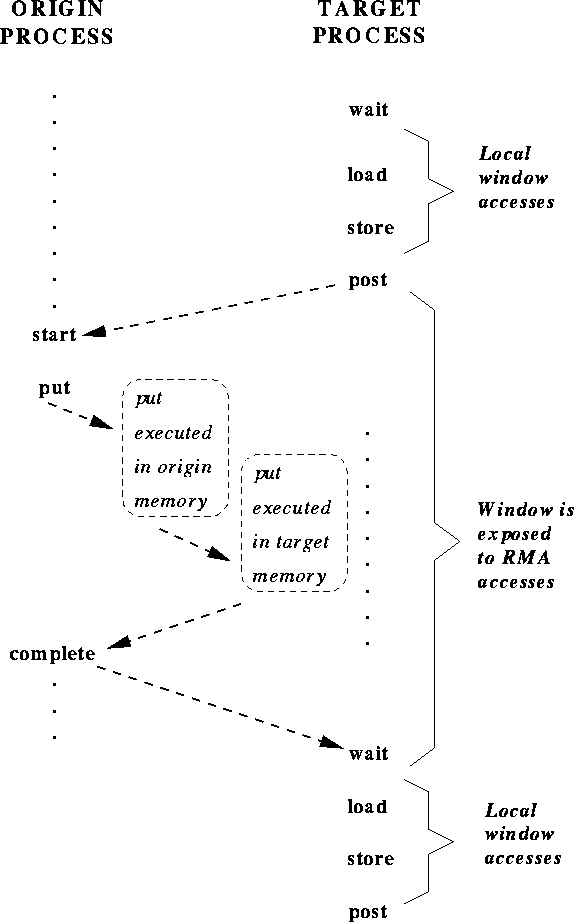
Figure 1: active target communication. Dashed arrows represent
synchronizations (ordering of events).
The synchronization between post and start ensures that the put call of the origin process does not start until the target process exposes the window (with the post call); the target process will expose the window only after preceding local accesses to the window have completed. The synchronization between complete and wait ensures that the put call of the origin process completes before the window is unexposed (with the wait call). The target process will execute following local accesses to the target window only after the wait returned.
Figure 1 shows operations occurring in the natural temporal order implied by the synchronizations: the post occurs before the matching start, and complete occurs before the matching wait. However, such strong synchronization is more than needed for correct ordering of window accesses. The semantics of MPI calls allow weak synchronization, as illustrated in Figure 2 .
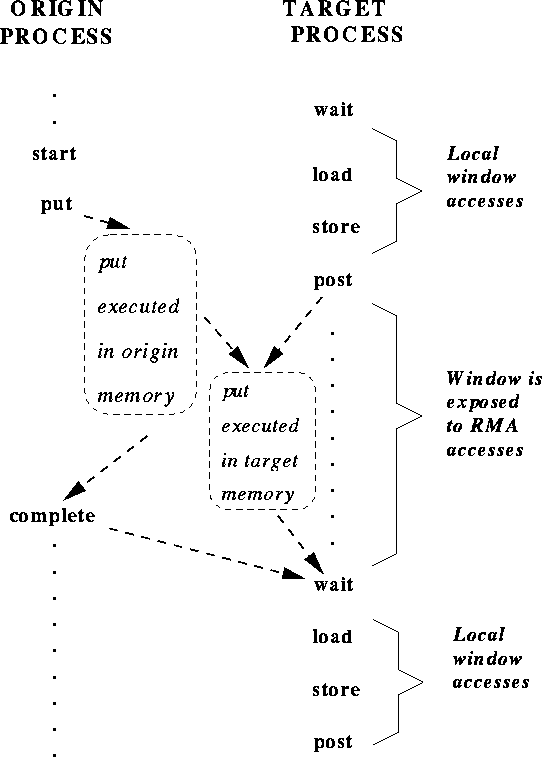
The access to the target window is delayed until the window is exposed, after the post. However the start may complete earlier; the put and complete may also terminate earlier, if put data is buffered by the implementation. The synchronization calls order correctly window accesses, but do not necessarily synchronize other operations. This weaker synchronization semantic allows for more efficient implementations.
Figure 3 illustrates the general synchronization pattern for passive target communication. The first origin process communicates data to the second origin process, through the memory of the target process; the target process is not explicitly involved in the communication.

Figure 3: passive target communication. Dashed arrows represent
synchronizations (ordering of events).
The lock and unlock calls ensure that the two RMA accesses do not occur concurrently. However, they do not ensure that the put by origin 1 will precede the get by origin 2.