并行系统运行支持库比较
王勇、李晓明
北京大学计算机科学技术系
摘要:本文主要从应用范围、针对的问题和实现的效率等几个方面对当前几种流行的并行系统运行支持库进行了比较。对Hpspmd程序设计模型的运行时支持库设计有很好的参考价值。
关键词:Runtime Library, Adlib, Data Parallel
![]()
一、前言:
自从出现计算机以来,人们就一直怀有一种对高性能计算机的渴望和追求,希望用这样的计算机在可容忍的时间内高效地解决那些计算密集型的问题。在不断的尝试中,特别是在近十几年的研究中,人们从机器硬件、体系结构、操作系统、编译器、编程语言、算法以及程序设计范型等不同角度提出了许多提高系统计算性能的方法。其中,并行技术作为高性能计算的一个最重要的方向,正在迅速的发展。在美国加州理工大学的C3P项目中,科学家们通过广泛的实验和研究,肯定地做出了“并行计算机可以有效地解决大规模的科学计算问题”的结论(参见由Geoffrey C. Fox等所著的“Parallel Computing Works”)。而且我们可以预言,在不久的将来,并行技术将成为推动计算机向前发展的一个巨大动力。
但到目前为止,虽然已经开发出了许多不同体系结构的并行机,在这些计算机上进行编程仍然是它们得以普遍应用的一个障碍。因此,人们提出了不同的并行程序设计模型试图解决编程方面的问题。
严格的说,程序设计模型是指程序员在开发一个并行程序时所看到和用到的(Huang Kai)。主要划分为共享变量模型、消息传递模型、数据并行模型、面向对象模型等几种。
|
几种并行程序设计模型的比较 |
|
|
1.共享变量模型与传统的顺序程序设计有许多类似之处。程序员只需关心划分程序中的并行性,而无需关心进程数据交换问题。适合采用该模型的并行系统一般为共享存储多处理机,如对称多处理机(SMP)。
2.消息传递模型是指程序中不同进程之间通过显式方法传递消息来相互通信,实现进程之间的数据交换、同步控制。它适用于多种并行系统,如多处理机、可扩展机群系统等。 3.数据并行模型是指将数据分布于不同处理单元,这些处理单元对分布数据执行相同的操作。数据是预先分布好的。按照并行成分的粒度大小及采用的操作方式,可以分别在SIMD和SPMD的计算机上实现。数据并行操作的同步是在编译时而非运行时完成的。 4.面向对象模型基于消息传递,但并行处理单位是对象。 | |
对一个并行程序设计模型来说,通常包含语言接口和运行支持库两个部分。其中,运行支持库是指建立在底层消息传递接口之上的一个用C,C++或Fortran语言编写的类库,为程序员提供并行程序开发所需的函数库或类库,它对整个系统的执行效率起着非常重要的作用。下图是并行程序设计的结构图,从图中我们可以看到运行支持库的位置。
![]() 高级语言接口
高级语言接口

(运行时支持库接口)
运行时支持库

MPI(PVM)通信支持
图1 运行时支持库的一般结构
目前,由北京大学自主开发的并行编译器P-HPF使用美国Syrause大学开发的Adlib作为运行支持库,其底层是建立在MPI消息传递接口之上的,适用于SPMD的计算机。同期存在的其它几种比较流行的,适用于不同环境的支持库还有CHAOS,GA,DAGH等,它们在应用环境,处理问题类型以及执行效率等方面均有所异同和专长。本文试给出目前这几种流行的并行系统运行支持库的一个较全面的比较。
二、两种类库概述:
这里,我们将目前存在的数据并行程序设计运行时支持库分为两类:第一类支持库有Adlib,Global Array等,它们主要为带有规则分布式数组的并行程序提供底层支持,强调为特定类型的程序设计模型提供高层通信原语,而不是具体的数值算法。第二类支持库主要用来提供对非规则问题的支持,包括CHAOS和DAGH等。
1. Adlib and Global
Arrays:
(1)Adlib
Adlib早期的开发工作是在英国Southampton大学的shpf项目中进行的。之后,在Syrause大学的PCRC项目中,Adlib库又经重新设计和实现,以NPAC PCRC运行支持库的形式发布。Adlib是一个针对数据并行程序设计的完全由C++实现的类库,用来支持数据并行语言编译器的实现。Adlib提供了一个简洁的支持HPF 1.0完整定义的分布式数组模型,并提供了一个对分布式数组的参数化方法和处理这些分布式数组的集合操作函数库。Adlib通过调用MPI提供的通信函数接口来完成各种通信功能,并实现了许多比MPI更高级的通信模式,比如树通信和随机存取通信,从而极大的方便了程序员的使用,同时还保证了运行的效率。另外,Adlib可以直接作为一种数据并行编程语言,其自身提供了一个完整的并行程序设计环境,适用于基于分布式存储的SPMD计算机。简单来说,Adlib是一种可以对HPF等数据并行程序设计语言提供运行时支持的高层类库,同时Adlib本身还是一个支持Spmd程序设计模型的系统。
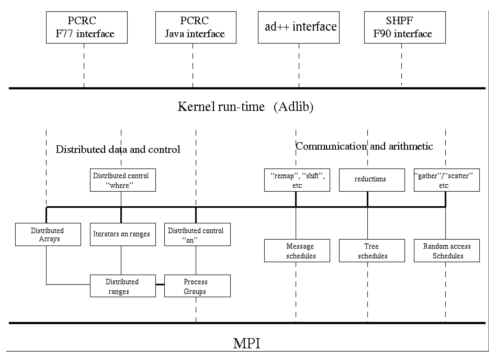
图2 Adlib的结构图
Adlib中的一个最重要的概念是DAD,它用来向运行支持库提供包含一个分布式数组各种相关信息的数据对象。换句话说,为了正确地调用库函数,应该做哪些准备来把面向程序员的全局信息反映到局部结点程序中,应该如何设计参数的结构等。这里的全局信息包括分布式数组的基地址,数组元素的类型,数组的维数以及数组的存放次序是行优先还是列优先等。也就是说,通过DAD类结构,完成了对数据分布的描述。
其次,Adlib提供了对分布式控制的支持。只有当一个处理器拥有一个数组元素或其拷贝时,才允许该处理器对该元素进行直接操作。Adlib提供了ON,AT和OVERALL三个结构来支持分布式控制。
ON construct内的代码只有处在活动处理器集(Active Processor Group)包括的处理器时才执行。
AT Construct类似于ON Construct,但该结构的程序体只有在当处理器拥有分布式数组的某个处于具体位置的元素时才执行。
OVERALL Construct中对分布式数组索引范围内的每一个位置的引用理论上能够并行的执行。
再者,Adlib提供了一组丰富的通信调度和运算操作。Adlib中的通信调度都是集合通信操作(即通信是通过对分布式数组上的集合操作完成的),主要分为remap类、gather-scatter类和reduction类三类。而Adlib中的运算操作也是通过通信调度实现的。这些通信模式都是比MPI更高级的通信模式,可以有效的支持了SPMD模式的并行程序设计。
通过以上三点,Adlib提供了对数据并行程序设计的有力支持,能够很好地处理分布式存储环境下的程序设计问题。目前,P-HPF数据并行程序设计语言(HPF语言的扩展)已成功的实现了在分布式存储环境下的编译和执行等问题,经过编译后的源程序,在各节点机上通过调用Adlib底层支持库进行通信等工作而并行地完成计算任务。关于Adlib执行效率问题的讨论请参见《ad++―一种高效的并行程序设计运行支持库》。
(2)Global Arrays
Global Arrays(GA)工具集由美国Pacific Northwest National Lab开发。它为分布式存储的计算机提供了一个高效的、可移植的“共享存储”编程接口。GA的关键思想是:在一个MIMD并行程序中,每一个进程都能够独立地、异步地访问物理上被分布的数组的逻辑块,而不需要实际拥有数据进程的显式配合(也就是通常所说的单边通信)。从这一方面来看,GA类似于共享内存的程序设计模型。另一方面,GA模型也承认访问远端数据比本地数据要慢,因此它允许显式指明并使用数据的本地性。从这一方面来看,GA又类似于消息传递系统。
GA提供了一个二维分布式数组环境下共享内存的程序设计模型。从用户的角度来看,一个全局数组被当作存储在共享的内存中。数据分布信息、地址和通信的细节被包装在全局数组对象中。然而,每当数据的局部性更重要时,实际数据的分布和局部性信息可以被得到并被使用。
以下的应用目标激发了GA的开发:
l 除了数据并行外,可能还要求任务的并行性;
l 访问不能在单独一台机器的内存中存放的矩阵数据块;
l 任务的执行时间有很大的差异;
l 计算与数据移动相比占非常大的比率。
目前,GA支持三种不同的环境:
1.带有中断驱动的基于分布式存储、消息传递的并行机;
2.带有简单消息传递机制的联网工作站机群系统;
3.基于共享存储的并行机
GA中的操作分为全局集合操作和非集合操作。其中,集合操作必须同时被所有的进程调用,就象在SIMD程序设计模式中一样; 而非集合操作可以在任务并行的MIMD程序设计模式中被任何进程调用。
与数据并行语言不同,GA允许任务并行地访问分布式数组,包括不同任务同时对覆盖区的归约操作。与Linda不同,GA提供了对求和归约和对覆盖区访问的高效支持。与共享虚拟存储机制不同,GA需要显式的函数调用来访问数据,但避免了操作系统保存内存一致和处理缺页故障的开销,并允许数据的同时传输。与Active Message不同,GA没有处理器之间的协作概念,从而GA 在共享存储的系统中也可以高效的执行。
GA库已经成功的在许多不同的计算机系统下得以实现,其中包括Intel DELTA, Paragon, INM SP-1, Kendall Square KSR-2以及NOW。但起初,GA是直接在与系统相关的通信机制上实现的;GA提供的单方通信是紧紧地针对二维分布式数组而实现的,且仅支持BLOCK分布,从而妨碍了GA的可扩展性。目前结合Adlib对数据(分布式数组)的表示能力重新改写GA的工作已经取得了一些进展,从而使GA可以支持更高维的数据和其它的分布方式。
GA模型非常的流行和成功,曾经作为许多并行应用的主要程序设计模型。这其中包括有近50万行代码的大型应用。应用的方向包括量子化学、分子动力学以及金融计算等诸多方面。
3. DAGH和CHAOS
前述几种运行支持库对规则问题都提供了不同程度支持。虽然规则问题是并行应用中的一个重要部分,但这并不是说并行应用中只有规则问题。许多重要的问题都包含一些非常不规则的,用类HPF的规则分布式数组并不能很好描述的数据结构。下面的两个运行支持库是专门针对非规则问题而设计的。
(1) DAGH
DAGH(Distributed Adaptive Grid Hierarchy)是由美国Texas大学Austin分校开发的为the Binary Black Hole NSF Grand Challenge Project等几个大型工程而设计的计算工具集。作为一个面向对象的,并行结构的可适应性网格优化方法的软件基础框架 (例如, Berger-Oliger AMR),DAGH采用一种独特的基于空间填充曲线的分解方法来表示可适应网格分层结构。
它提供了利用可适应性网格优化方法(Adaptive Mesh Refinement,AMR)解决偏微分方程系统的框架。计算可以按用户的要求串行地或并行地执行。在并行的情况下,DAGH接管通信工作,更新在component grids边界的阴影区。同时,DAGH还提供了一个编程接口,从而这些计算可以被传统的Fortran 77/90或C/C++来调用执行。
从结构上来看,DAGH提供了实现可适应性网格优化方法的类库。同时,它还提供了在并行处理器上运行并行应用的结构框架。所有用DAGH作为基本结构建立的应用都有同样的结构,由一个C++的主驱动构成,其中包括用C,C++或Fortran实现的计算例程。这一结构可以被看作一个为由用户提供的面向应用例程的模板。为了建立一个基于DAGH的应用,必须要提供以下几个部分:
l 驱动程序
l 执行网格级操作的程序
l 执行网格内操作的程序
l 其它的实用操作
l 差错估计例程
l 输入参数文件(可选)
l makefile
下图为DAGH的设计模型图。DAGH的结构层次中融入了分层抽象和问题分离的原理。
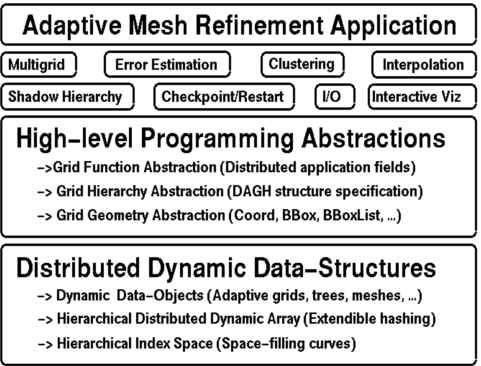
图3 DAGH的设计模型图
其中每一个层可以被想象为一组抽象的数据类型。最低层定义了一个分层的动态分布数组(hierarchical dynamic distributed array,HDDA) ,它是我们熟悉的静态数组的一个 generalization,有创建、删除、数组扩展和压缩和数组访问等操作。在HDDA上定义了一个实现grids and/or meshes操作的层。这些操作直接被翻译为对 HDDA层实例的操作。
在DAGH中,数据结构抽象使用HDDA。HDDA又由三个抽象构成,分别为索引空间、存储和访问。HDDA中的项对应DAGH中的数据块。
(2) CHAOS:
CHAOS是由美国Maryland大学开发并完成设计的一个适用于解决非规则问题的运行支持库。其设计目标系统是任何支持消息传递的基于分布式存储的系统或者基于分布式共享内存的系统。目前CHAOS已在Intel iPSC/860和Paragon, IBM SP1/2, TMC CM5, Cray T3D, Stanford DASH, NOW 上得以实现。
对于非规则问题,如果利用目前的并行编程语言的描述能力和数据分配形式对非规则数组进行分配,对应的计算划分所产生的通信形式往往是不规则发生的,且通常为细粒度通信。因此,如果按照处理规则问题的方法去处理非规则问题,其效率必然非常低下,需要寻找体现非规则问题特点的处理方法。CHAOS提供了一种非常典型的处理非规则问题的模型:inspector/executor模型。
CHAOS库包括用来选择最优的数组到处理器映射的分解者(partitioner),用来重新映射输入数组以达到最优划分的函数以及优化处理器间通信的函数。在数据被重新划分以后,CHAOS分为两个阶段。 inspector阶段分析对数组的非规则引用中出现的索引数组或间接数组的访问模型,并生成一系列优化的通信计划;Executor阶段负责执行这些嵌入到程序中的与通信有关的函数。
分布式数组的分布模式对系统的性能有非常重要的影响,因为它们决定了处理器之间通信的模式。划分数组为恰当的非规则方式通常是非常有利的。CHAOS提供了将数组映射到处理器上的原语,并使用转换表(translation tables)来描述分布式数组的分布情况。CHAOS的通信工作也是基于这些转换表进行的。转换表为每一个分布式数组建立全局索引―处理器对应表和全局―局部索引对应表,通过查表来决定间接引用的数组元素是否为本地的以及具体在哪个处理器上,而且可以更进一步地决定数组元素在处理器内存中的存储位置。
CHAOS提供了许多原语以有效地处理非规则问题。这些原语使程序员免除了对底层细节的考虑,并使问题的实现得以简化。CHAOS还提供了一组在运行时执行优化的原语来降低消息的数量和处理器间通信的容量。这些原语检查每个处理器发出的数据访问请求,计算有那些数据为非本地数据以及这些数据存储在扫描地方,然后生成通信计划以指明通信的模式来交换数据。一旦通信计划就绪,高效的gather/scatter例程就被调用以在处理器之间交换数据。
四、结论
以上就是对目前流行的运行支持库的一个概要的叙述。针对不同的并行应用目标和运行环境,程序员应该选择合适的支持库。
目前,还有许多问题仍需要改进。如GA对多维分布式数组的支持,对非规则问题支持库的改进等等。这方面的工作正在进展中。但我们可以期待,在不久的将来,运行支持库良好的可移植性、可扩展性、易用性、高效性和可靠性必将使并行程序设计得到更快、更广的发展和应用。
参考文献
1. Bryan Carpenter,Programming in ad++(DRAFT), Technical report, NPAC, Syrause University, NY, April, 1998
2. Bryan Carpenter, Guansong Zhang, and Yuhong Wen. NPAC PCRC runtime kernel definition. Technical Report CRPC-TR97726, Center for Research on Parallel Computation, 1997.
3. http://www.npac.syr.edu/projects/pcrc.kernel.html
4. Jaroslaw Nieplocha, Robert J. Harrison and Richard J. Littlefield, Global Arrays: A Portable “Shared-Memory” Programming Model for Distributed Memory Computers, Pacific Northwest Laboratory, Richard WA, 1994
5. Joel Saltz, Ravi Ponnusamy, Shamik Sharma, Bongki Moon, Yuan-Shin Hwang, Mustafa Uysal, Raja Das, A Manual for the CHAOS Runtime Library , University of Maryland: Department of Computer Science and UMIACS Technical Reports CS-TR-3437 and UMIACS-TR-95-34 , March 1995
6. Shyamal Mitra, Manish Parashar, & J.C. Browne , DAGH: User's Guide, Department of Computer Sciences , University of Texas at Austin, 1998