
并行计算的基本问题与现状 -- 1995
技术
最热门的行业都是在需求和技术更新这双重的推动下前进的,在高性能计算领域中也不例外.在很多应用领域中对计算能力的需求越来越高,这在很长一段时间内将依靠大规模并行处理来解决.短时间内因为现有的算法和软件还不能支持并行计算,所以需求和技术这两种推动作用的关系可能还不明朗.然而,并行性最终必将在所有的计算机中体现出来--包括儿童游戏机、个人计算机和工作站以及超级计算机等.
这种技术的推动力量来自于VLSI,就是超大规模集成技术,正是这种技术在上一个十年内开创了个人计算机和工作站的市场.在1980年,Intel公司的8086处理器用了50,000晶体管,而在1992年最新推出的RISC芯片Digital alpha中,包含了1. 7*106个晶体管,增长了30倍.在1995年,167Mhz主频的Ultrasparc芯片包含了5 .2*106个晶体管,其中用于CPU与cache的比例为2:1.芯片内晶体管密度的大幅度提高和主频的日益加快使得现在用于科学计算的芯片性能比1980年初期的8086和8087芯片组件提高了5,000倍.
导致芯片集成度提高的根本原因在于芯片特征尺寸(feature size)的不断减小.1992年alpha芯片的特征尺寸为0.75微米,到1995年Ultrasparc 的特征尺寸则降到了0.5微米,而且这种趋势仍在持续发展.预计到2000年,一个芯片内的晶体管数目可望达到50,000,000个.那么我们能利用这些晶体管做些什么呢?
在对一个包含一百万个以上晶体管的芯片进行布局时,设计师们能将大多数主要功能模块集成到一个只有2cm2的芯片中,这可以使个人计算机和工作站的性能有一个很大的提高.如果想将芯片内晶体管的密度再提高10倍,则必须通过某种并行性来实现,如在一个芯片中重置多个CPU部件.
到2000年,并行性将在所有的计算机中体现出来.目前,当我们制造一台超级计算机时,总是用多个CPU和多块印刷板来构造一个处理器阵列,阵列中的每个节点都是一个不同类型的处理器.图1中展示了一个nCUBE结构的并行超级计算机,它的每块印刷板都有64个节点,每个节点由一个CPU芯片和附加内存组成.但要想使之实用还必须通过某种形式将其连接起来,这也是目前研究的一个热点.接下来我们将讨论哪些节点最应当被重复使用以提高性能,是象图1那样重复设置一些较小节点,还是重复设置一些“胖”节点,就象IBM SP-2、CRAY T3D 、Thinking Machines的CM-5和Intel的Paragon那样每个节点都是一个复杂的多芯片的印刷线路板.另外一个要讨论的问题是如何将这多个处理器连接起来.它们可以是nCUBE结构中的紧耦合hypercube网,也可以是连接常规计算机的复杂的已经建立好的局域网.然而这些问题不应当掩盖这样的一个基本点:并行性可以帮助你建立一个全球上最快的和最为经济的超级计算机.图2以时间为函数描述了这一点,如今的并行机比常规的超级计算机性能提高了近10倍.
图1: nCUBE-2节点与主板.在一台超级计算机上最多可以有128块这样的主板
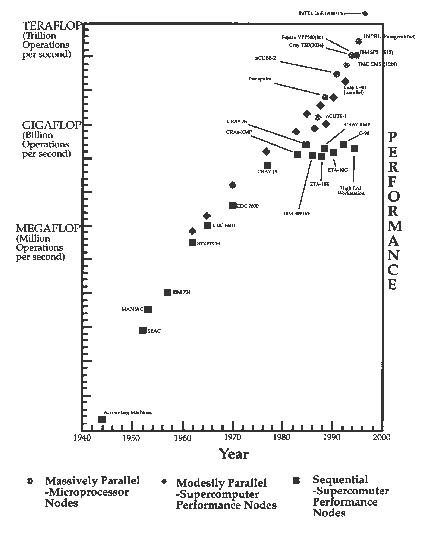
图2: 并行与串行超级计算机的性能
如今并行性可能仅对于超级计算机厂商和用户来说是关键问题.到2000年,所有超级计算机都将使用融入了并行性的硬件、算法和软件.作为回报,我们将得到令人惊异的性能,同时也开创了一个崭新的领域.此时,价格将成为重新设计并实现软件、算法和应用程序的一个主要问题.
巨大挑战
1992年,联邦政府开始了其高性能计算与通信的五年计划.这极大地促进了上述技术的发展,并将注意力集中于图3中所列举的一些重大问题的求解上.这些都是科学和工程领域中的基本问题,在经济和科学双重推动作用下,利用高性能计算技术和资源必将大大地促进这些问题的求解.
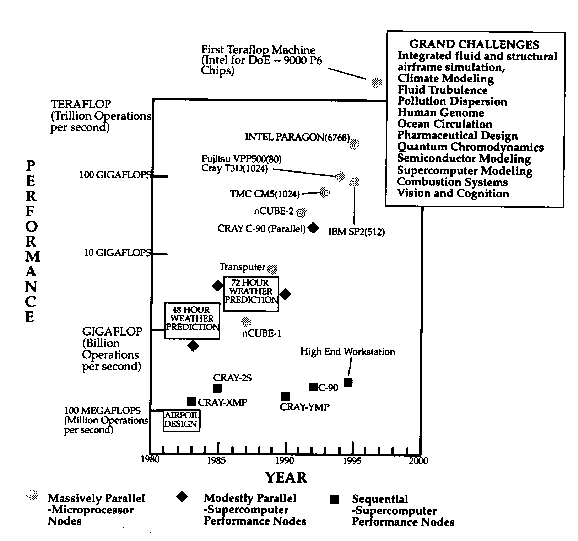
图3: 巨大挑战性应用.并行超级计算机的出现将可以求解一些困难的应用问题
在这个计划中,联邦政府的几个机构彼此之间互相协作.ARPA负责开发基本技术,将用于DOE、NASA、NSF、NIH、EPA和NOAA对一些重大问题的求解中.许多这样的机构都对技术的发展起了关键的作用.如DoD已经建立了一个基本的现代计算机程序模式,它将HPCC的技术集成到了它的基础设施中.在这项计划中,选取的对象有DOE和NOAA的天气模型、NASA的耦合结构、空气动力学仿真和高速城市交通等.
1996年联邦政府的蓝皮书中记载了在对巨大挑战性问题研究中已取得的成果,它们可以在Web上访问得到.然而,目前更多的注意力已经转移到了另外一些问题上,即所谓的国家级挑战性问题,它重点强调大规模信息处理和分布式系统.这些领域包括数字图书馆、医疗保健、教育、制造业和关键的管理领域,以及一些在HPCC技术推动下产生的一些行业,尽管它们不是一些关键问题.
著名的并行计算机
对自然和社会中并行性的研究将对我们设计和使用并行计算机产生一定的作用.事实上,我们可以把社会或文化看成是一些使人们能并行地、高效地和协调地工作的规则或习俗的集合.
我们通过对一个大的计划-航空飞行器计划的描述来简单说明这个问题.如果能雇用一个超人来独立完成此计划想必一定是很诱人的,但在实际中这是不可能的,所以不得不由一些普通人来完成,有时可能需要100,000个普通人.这些人并行工作来完成航空飞行器的制造.并行计算机与这非常相似,在设计一个新的飞行器时,我们可以用1015个数字计算机一起工作来完成其空气动力学的仿真工作.在NASA飞行器计划中,管理成为关键问题.类似地,在计算机科学中,硬件与软件的结构也是一个关键的研究问题.
我们可以将大脑看成一个具有1012个神经元的并行计算机,它们可以协作工作进行信息处理和决策;只不过是神经元之间的连接是轴突和树突而不是导线和印刷电路板连接而成的nCUBE结构.但它们之间还是有很类似的共同点的,各互连元素间都采用了消息传递方式进行通信.将来的并行计算机都将使用数据并行机制来并行地求解问题.
数据并行
开发并行计算是因为它们基于一个统一的机制叫作区域分解或数据并行.在自然界中对一个复杂的问题进行求解时是将它分割成若干块,然后将不同块分配给一个或一组特定的神经元.图4中对此进行了描述,它表明,大脑的不同部分负责求解来自身体不同部位的信息.视觉信息是大脑处理的主要任务,它是从视网膜接收到的物体各个像素的光信息到大脑神经元的空间映射.

图4: 大脑(老鼠)中的三种并行计算策略.每个图对应着不同功能的大脑活动情况[Nelson:90b]
在图5所示的对相互作用的粒子进行并行仿真中应用了并行,它将不同的粒子分配到并行计算机中的一个特定节点上.图5中的天体物理学的仿真是非常不一致的,而且与一个节点相对应的空间区域是不规则的且与时间相关.这里的复杂性是非常高的,但据此编制的程序却实现了一个很好的性能,在1024个节点上的加速比为800.

图5: 宇宙模型的二维投影,演示了二个银河系的碰撞[Salmon:89b]
许多大规模计算,如化学和电磁学,包含了很多的产生和处理大规模矩阵的计算.能级计算包括数据散播时的特征值求解都将涉及到矩阵乘法和线性方程求解.因此这里也应用了数据并行的概念,如图6所示,将矩阵按规则方式分配到各个处理机上,并行性在不同节点内矩阵元素的独立产生、特征值求解和对其他矩阵的操作中都有体现.通用的矩阵运算库 -- SCALAPACK已经可以应用于一大类高性能的向量与并行计算机上.

图6: 在4*4并行计算机阵列上进行16*16的矩阵分解
作用于如此大数据区域的算法的性能也是一个主要问题.数据并行通过将区域划分成小块并将算法分别作用到每一个点上来实现并行性.
当前的并行机
随着工作站市场上供应商们不断地推出他们新的机器模型,并行计算领域也在大幅度地发生变化.进一步讲,随着不同设计方案和软件的推出,任何机器模型可能在几个3年以后变得过时.这里我们讨论一些1995年受到广泛关注的机器,它们可以分成三大类.第一类即所谓的SIMD,单指令流多数据流计算机或同步计算机,即一个带有分布式内存和处理单元的耦合阵列,如每个处理单元都与它自已的内存相关联.在SIMD机器中,每个节点都执行相同的指令流.MP-2最多可以有16K个32位的处理器及1G(109字节)内存,相应的峰值速度可以达到6GFLOPS(每秒钟109次浮点操作).Thinking Machines的CM-1、CM-2和CM-200及AMT DAP都是分布式内存的SIMD型机器.
分布式内存的MIMD机器结构是第二大类很重要的结构,最近的MPP(大规模并行处理机)就是以此为基础设计出来的,它的内存结构与处理能力都是物理上分布的.属于这种类型的一个代表性机器是Thinking Machines生产的CM-5,如图7所示.它们与上面所说的SIMD型体系结构有着根本的不同.MIMD型体系结构满足了大多数应用中要求每个节点执行自已不同指令流的需求,因此发展速度很快.CM-5的最高配置可以有1,024个节点和32G内存,在某些应用场合中可以达到80GFLOPS.另外,最近安装在Cornell大学由IBM生产的512个节点SP-2实现了比安装在Los Alamos最高配置CM-5更高的性能.这表明了高效利用各个节点能力的重要性.如在IBM的机器中,各节点是一个功能强大的型号为RS 6000的RISC芯片.CM-5就是在很大程度上受它各节点特定的VLSI限制,即使它的硬件设计十分优化,也很难在这么短的技术周期内生产出支持其特殊硬件结构的相应软件.设计任何新的体系结构都必需注重这样一个事实:随着VLSI技术的发展,每18个月在结构上不做任何变动的情况下,其性能就可以提高一倍.当前的机器,除了nCUBE外,都将它们的并行系统建立在目前非常流行的PC机和工作站技术基础上--如IBM(RS6000)、CRAY(Digital alpha)、Meiko(Sun)、SGI(MIPS)和Convex(HP)等.Intel也宣布用他们的P6芯片构造一个名为DoE的TeraFLOPS级的计算机,在两个芯片模块中要集成超过10,000,000个晶体管.之后,一大系列的机器都将建立在i860芯片组上,其中包括安装在Sandia的由Intel生产的Delta Touchstone系统,这是一个1,840个节点的系统,所图8所示,它是第一个有着特殊影响的大规模MPP系统的产品.有趣的是,由于Intel公司生产的DoE是为了对现有核武器进行仿真试验,在那里不允许进行性能测试,所以有关它的一些持续性能及维护情况目前还不清楚.

图7: Thinking Machines制造的CM-5

图8: 安装在Caltech的并行超级计算机"Delta Touchstone",由Intel生产.这个系统采用mesh结构连接了512个节点,它是Paragon的原型机
所有上述讨论的并行计算机都是可扩展的,它们的规模可以从价格为100,000美元的较小规模到30,000,000美元的最大规模,其节点数与性能也是随着其价格线性增长的.尽管在设计中优化方法不同,由于各个机器都采用相似的VLSI技术,所以他们的性能价格比基本上相同.所图2中所示,它们的性能价格比比起通常的向量超级计算机(如来自Cray、IBM和日本某些厂商的计算机)要好的多.这些来自于Cray和日本厂商的向量超级计算机也是并行的,如非常成功的Cray C-90就是一个最多可以有16个节点的计算机,它们是共享内存的MIMD型机器,所有的处理器都将访问同一个全局内存.
这种共享内存的MIMD型机器是体系结构中的第三大类.在向量超级计算机中,所选用的每个节点运算速度都尽可能地高,这将会减少最终交付系统的节点数目(在给定的价格条件下).这类共享内存的机器包括Silicon Graphics(SGI)的Power Challenge系统,它的主要销售对象是市场中的最终用户,正是它使得SGI在当前高性能计算领域中有着越来越大的影响.相应的,共享内存的体系结构也受到了越来越多的关注.共享内存体系结构受限制的是它的不易扩展性,如实现它的总线,这样的系统节点数目最多为16-32个.而且随着节点性能大幅度地提高,一个价格在200万美元上下的普通32个节点的共享内存系统对很多用户来说都是一台超级计算机.共享内存系统的另一个优点是它容易实现诱人的软件环境.所以许多人期望这样的系统起到越来越重要的作用并将成为主流MPP系统的重要特征.Burton Smith最新设计的Tera级的共享内存的超级计算机实现了一个特殊的流水线算法,使得所有处理器能同时访问存储系统的所有部分.而且,更多人还期望有着非均匀性存储访问时间的群集或虚拟共享结构的出现.这样的机器,如Convex Exemplar、新的SGI系统、Stanford的DASH实验系统以及现在已经消失的Kendall Square的KSR-1, 2等,都是分布式存储结构,但是一些特殊的硬件和软件使得这些分布式内存对所有处理器来说都相当一个全局空间.
当前,主要的并行计算机厂商来自于美国,它们的主要竞争是来自于欧洲的建立在transputer芯片上的计算机.日本厂商对此领域的贡献很小.但是随着技术的进一步成熟,我们期望他们在竞争中起到重要的作用.
工作站群集系统 -- 非正式的超级计算机
上面我们主要讨论了由特殊的高速网络连接起来的系统,它们采用了商用PC机和工作站中的技术.现在很多人热衷于研究由普通网络如以太网、FDDI、或ATM连接起来的非正式并行系统.这些被称作为COWs或NOWs(clusters or networks of workstations)的系统很明显是非均匀存储访问的MIMD型的分布式存储并行计算机,它们应该能运行为IBM SP2或Intel Paragon设计的任何软件或并行算法,只是后者具有更高的通信带宽和更低的通信延迟,这样它们能高效地支持更多类型的应用.COWs变得所此吸引人是因为实验表明它能很高效地执行一些并行任务,而且它们不受政策与经济条件的限制.COWs可以由那些在晚上或周末时"空闲"的PC机或工作站组成.事实上,由台式计算机构成这样的系统无需任何额外的投资.
上述的想法可以实现元级计算(metacomputing),即利用通过网络连接的任意数目的异构计算机来联合求解一个问题.
最好的体系结构
上述提及的各种类型机器和结构都有着自已的长处和缺限,因为它们按照不同的方式进行了优化处理.
共享和虚拟共享存储系统使得软件设计变得很容易,尤其是对那些已经存在的Fortran源程序,但是事实已经证明,很难在保证其性能价格比的前提下将它们扩展成为更大规模的系统.不过很多人相信硬件技术的发展将改变这一看法,比如:基于共享存储的MPP系统就是和当前超级计算领域中增长很快的分布式存储系统相对立的.
数据并行是最早提出的适合于分布式存储计算机的方法,但重要的是研制出能开发问题内在并行性的编译器.分布式存储的机器很容易扩展成更大规模的系统,配备上相应的软件即能在其上求解更大规模的问题.实际应用中应该根据应用问题类型的不同在选择SIMD型或MIMD型机器之间作一折衷.规则性问题,如图6中的矩阵操作就比较适合于SIMD型机器;而MIMD型机器对规则和不规则问题都比较合适,如图5中粒子运动的仿真.1990年时我们估计接近一半的已研制的大规模超级计算机仿真时采用了SIMD结构,而另一半则采用了更为灵活的MIMD结构.为适应不规则的算法,注意力已经越来越多地从SIMD型的体系结构转移到了MIMD型的体系结构.
为了同时集成不同种结构的特点,硬件与软件还在继续发展中.在将来,用户期望不同种类的计算机都提供一个相同的应用界面,尽管目前还不清楚MPP和异构的超级计算机是否能高效率地支持同样的软件模型.用户将可以象选择常规的计算机一样,根据不同的应用和机器性能选择不同的并行计算机,而不会再象过去那样面对那些为支持不同的硬件设计方案而设计的完全不同的软件环境.将来的体系结构发展将在提高性能的同时,把一些关键性问题如共享存储时的说明等,从软件转移给硬件进行处理.这也可以使用户在不改动软件模型的基础上获得更高的性能.
软件
作为将来主流计算工具的并行计算机面临的问题是缺乏运行于其上的软件支持.许多成功利用并行计算机的实例都来自学术界与科研界,其软件代码基本上都少于10,000行,并且所需要的软件和算法都是专门设计的.要运行更大规模的程序,如运行100,000行到1,000,000行的工业应用程序代码就是一件非常困难的事情.
需要对软件进行重新改造很明显是广泛采用并行计算机的主要阻碍.利用在可移植、可扩展的语言及软件环境研究中所取得的成果,我们可以重新实现或重新设计能很好地运行在于当前的并行计算机上的应用软件.
在编程语言方面,比较统一的观点是对现有的语言进行扩展,而不是开发一种新的并行语言.这里我们将简要讨论一个Fortran语言,类似的工作在诸如C、C++、Ada、Lisp等语言中也有体现.目前对Fortran语言的扩展基本有两种模式,我们将依次讨论.
数据并行Fortran
这里,并行性体现在对数组中各个元素的操作可以由用户定义的或系统自带的库函数分别独立地计算,如对数组或向量进行的加法和乘法操作.用户可以通过一系列命令使编译器对分布于并行处理机中数组的各部分同时进行操作.AMT、Maspar和Thinking Machines生产的SIMD型机器最早推出了这种语言,如CM Fortran.这些思想也已经应用于MIMD型的系统.最近研制的数据并行语言可以处理复杂的不规则应用问题.遵循工业标准的HPF或高性能Fortran已经被采用,并推出了第一个商用编译器.高性能Fortran为用户提供了一个统一的软件环境,允许用户独立于上述不同体系结构的计算机上开发应用程序,这就是所说的可扩展、可移植的软件系统.
消息传递Fortran
我们期望数据并行Fortran将最终高效地支持科学领域与工程仿真等一大类问题的求解.然而,对编译器要求比较低的一种方案是对Fortran进行扩展,用户可以简明实现在MIMD型机器中的消息传递.这种"Fortran+消息传递模型(Fortran+MP)"能在常规计算机上进行问题求解.对用户来说,消息传递Fortran程序要比数据并行Fortran程序需要更多的编制时间,并仅适合于MIMD型机器.然而,在一大类分布式或共享存储的MIMD机器中,利用了消息传递系统如PVM和最新的工业标准MPI(Message Passing Interface).Fortran+MP可以具有非常好的可移植性和可扩展性.一些超级计算技术及World Wide Web技术的应用更为这一领域的工作增添了诱人的色彩.
分布式计算和操作系统
并行机上的真正软件环境还必须提供除常规计算机用户所关注的并行编程语言之外的许多其他服务.SIMD机器操作服务通常由UNIX的主机完成,而MIMD到目前为止也大都采用了host-node机制.IBM的SP-2从开始就采用了一种完全不同的策略,它将UNIX的处理能力分配到各个节点上,这就使得整个计算机既可以看成是一个高度耦合的并行计算机,也可以看作是一个分布式系统.这里仍然存在着一个将两种并行性集成到其支持软件中的问题.而且,将COWS、超级计算和MPP自然连接起来进行计算在将来可以会成为一种趋势.
操作系统服务
现代并行计算机都提供了并行磁盘系统,它可以为图2中所示的很多领域中的高性能计算提供相适应的可扩展的磁盘I/O性能,访问这种并行磁盘系统的软件和方法也是一个基本问题,需要进一步研究.开发可扩展的I/O系统最先是由Caltech的Messina倡导的.商业领域中的关系数据库对此特别感兴趣,这在运行于分布式存储的多计算机系统(如IBM的SP-2)上的ORACLE数据库中已经充分地体现出来.
在此领域中,并行调试器也是很重要的,它是为调试科学与工程领域的并行应用程序而从顺序程序调试器扩展而来的;监视和估价并行机的性能也是很重要的,它可以显示妨碍并行机发挥其效率的各种因素;另外一些支持自动将任务分解并分配到各个节点的软件工具也亟待开发.
应用
许多并行机都应用于学术界和研究领域,他们深刻意识到了它的潜在能力,如果一旦被全球的工业界和政府应用所接受,则可以获得巨大的商业成功.这些在上述所提及的巨大挑战性问题中都有体现.
也可以说,并行计算给美国工业界在全球竞争中带来了许多机会,这也是美国为什么领先于欧洲和日本的原因.我们期望这项技术在19世纪90年代全球经济大战中成为一项秘密武器.
我们已经开发了一些属于HPCC的工业应用,这将在本书的其他部分讨论.Infomall--这项由纽约州技术转移活动所倡导的工作,强调了我们的希望 -- MPP在主要工业领域中的应用能对与大规模MPP数值仿真有关的信息领域起一个第二推动力的作用.
参考文献
[Andrews:91a] Andrews, G. R. Concurrent Programming: Principles and Practice. The Benjamin/Cummings Publishing Company, Inc., Redwood City, CA, 1991.
[Almasi:94a] Almasi,G.S.,and Gottlieb,A.Highly Parallel Computing.The Benjamin/Cummings Publishing Company,Inc.,Redwood City,CA,1994.second edition.
[Angus:90a] Angus,I.G.,Fox,G.C.,Kim,J.S.,and Walker,D.W.Solving Problems on Concurrent Processors:Software for Concurrent Processors,volume 2. Prentice-Hall, Inc.,Englewood Cliffs,NJ,1990.
[Arbib:90a] Arbib, M., and Robinson, J.A.,editors. Natrual and Artifical Parallel Computation. The MIT Press, Cambridge, MA,1990.
[Brawer:89a] Brawer, S. Introduction to Parallel Programming. Academic Press, Inc.Ltd.,London,1989.
[Chandy:92b] Chandy, K. M.,and Taylor, S. An Introduction to Parallel Programming. Jones and Bartlett, 1992.
[CSEP:95a] "Computational science educational project." Web address http://csep1.phy.ornl.gov/csep.html.
[Dongarra:94a] Dongarra, J.,van de Geign, R.,and Walker, D."Scalability issues affecting the design of a dense linear algebra library," J.Parallel and Distributed Computing, 22(3):523-537,1994.
[Doyle:91a] Doyle, J. "Serial, parallel, and neural computers," Futures, 23(6):577-593,1991.(July/August).
[Duncan:90a] Duncan, R. "A survey of parallel computer architectures," Computer, 23(2);5-16,1990.
[Foster:95a] Foster,I. Designing and Building Parallel Programs. Addison-Wesley, 1995. http://www.mcs.acl.gov/dbpp/.
[Fox:88a] Fox,G.C.,Johnson,M.A.,Lyzenga,G.A.,Otto,S.W.,Salmon,J.k.,and Walker, D.W.Solving Problems on Concurrent Processors,volume 1. Prentice-Hall, Inc., Englewood Cliffs, NJ, 1988.
[Fox:94a] Fox,G.C.,Messina,P.C.,and Williams, R.D.,editors. Parallel Computing Works! Morgan Kaufmann Publishers, San Francisco, CA,1994. http://www.infomall.org/npac/pcw/.
[Golub:89a] Golub, G. H., and van Loan, C.F. Matrix Computations. Johns Hopkins University Press, Baltimore, MD, 1989. 2nd Edition.
[Gropp:95a] Gropp,W.,Lusk, E., and Skjellum, A. Using MPI: Portable Parallel Programming with the Message Passing Interface. MIT Press, 1995.
[Hayes:89a] Hayes, J.P., and Mudge, T. "Hypercube supercomputers," Proceedings of the IEEE, 77(12):1829-1841,1989.
[Hennessy:91a] Hennessy, J.J., and Jouppi, N.P. "Computer technology and architectures: An evolving interaction," IEEE Computer, pages 18-29,1991.
[Hillis:85a] Hillis, W.D. The Connection Machine. MIT Press, Cambridge, MA,1985.
[HPCC:96a] National Science and Technology Council, "High performance computing and communications," 1996. 1996 Federal Blue Book. A report by the Committee on Information and Communications. Web address http://www.hpcc.gov/blue96/.
[HPF:93a] High Performance Fortran Forum. "High performance Fortran language specification." Technical Report CRPC-TR92225, Center for Research on Parallel Computation, Rice University, Houston, Texas, 1993.
[Hockney:81b] Hockney, R.W., and Jesshope, C.R. Parallel computers. Adam Hilger, Ltd.,Bristol, Great Britain, 1981.
[Koelbel:94a] Koelbel, C., Loveman, D.,Schreiber, R.,Steele, G.,and Zosel, M. The High Performance Fortran Handbook. MIT Press, 1994.
[Lazou:87a] Lazou, C. Supercomputers and Their Use. Oxford University Press, Oxford, Great Britain, 1987.
[Messina:91d] Messina, P., and Murli, A.,editors.Practical Parallel Computing: Status and Prospects. John Wiley and Sons, Ltd., Sussex, England, 1991. Caltech Report CCSF-13-91.
[McBryan:94a] McBryan, O. "An overview of message passing environments," Parallel Computing, 20(4):417-444,1994.
[Nelson:90b] Nelson,M.E.,Furmanski,W.,and Bower,J.M."Brain maps and parallel computers," Trends Neurosci.,10:403-408,1990.
[Salmon:89b] Salmon, J., Quinn, P., and Warren, M. "Using parallel computers for very large N-body simulations: Shell formation using 180K particles," in A. Toomre and R. Wielen, editors , Proceedings of the Heidelberg Conference on the Dynamics and Interactions of Galaxies, Springer-Verlag, April 1989. Caltech Report C3P-780b.
[Skerrett:92a] Skerrett, P. J. "Future computers: The Tera Flop race," Popular Science, page 55, 1992.
[Stone:91a] Stone, H. S., and Cocke, J. "Computer architecture in the 1990s," IEEE Computer, pages 30-38, 1991.
[SuperC:91a] Proceedings of Supercomputing '91, Los Alamitos, California, 1991. IEEE Computer Society Press.
[SuperC:92a] Proceedings of Supercomputing '92, Los Alamitos, California, November 1992. IEEE Computer Society Press. Held in Minneapolis, Minnesota.
[SuperC:93a] Proceedings of Supercomputing '93, Los Alamitos, California, November 1993. IEEE Computer Society Press. Held in Portland, Oregon.
[SuperC:94a] Proceedings of Supercomputing '94, Los Alamitos, California, November 1994. IEEE Computer Society Press. Held in Washington, D.C.
[Trew:91a] Trew, A., and Wilson, G. Past, Present, Parallel: A Survey of Available Parallel Computing Systems. Springer-Verlag, Berlin, 1991.
[Zima:91a] Zima, H., and Chapman, B. Supercompilers for Parallel and Vector Computers. ACM Press, New York, 1991.
Copyright 牋NPACT