| 4.6 分散(Scatter) |
MPI_SCATTER(sendbuf,sendcount,sendtype,recvbuf,recvcount,recvtype,
root,comm)
IN sendbuf 发送消息缓冲区的起始地址(可变,仅对于根进程)
IN sendcount 发送到各个进程的数据个数(整型,仅对于根进程)
IN sendtype 发送消息缓冲区中的数据类型(句柄,仅对于根进程)
OUT recvbuf 接收消息缓冲区的起始地址(可变)
IN recvcount 待接收的元素个数(整型)
IN recvtype 接收元素的数据类型(句柄)
IN root 发送进程的序列号(整型)
IN comm 通信子(句柄)
int MPI_Scatter(void* sendbuf, int sendcount, MPI_Datatype sendtype,
void* recvbuf, int recvcount, MPI_Datatype recvtype,
int root, MPI_Comm comm)
MPI_SCATTER(SENDBUF, SENDCOUNT, SENDTYPE, RECVBUF, RECVCOUNT,
RECVTYPE, ROOT, COMM, IERROR)
<type> SENDBUF(*), RECVBUF(*)
INTEGER SENDCOUNT, SENDTYPE, RECVCOUNT, RECVTYPE, ROOT, COMM,
IERROR
MPI_SCATTER是MPI_GATHER的逆操作.
其结果相当于根进程执行了n次发送操作:
MPI_Send(sendbuf+i*sendcount*extent(sendtype),sendcount,sendtype,i,...),
然后每个进程执行一次接收操作:
MPI_Recv(recvbuf,recvcount,recvtype,i,...).
另外一种解释是根进程通过MPI_Send(sendbuf,sendcount*n,sendtype,...)发送一条消息,这条消息被分成n等份,第i份发送给组中的第i个处理器, 然后每个处理器如上所述接收相应的消息.
对于所有非根进程,发送消息缓冲区被忽略.
根进程中的sendcount 和sendtype的类型必须和所有进程的recvcount和recvtype的类型相同(但它们彼此之间的类型映射可以不同).这就意味着在每个进程和根进程之间,发送的数据个数必须和接收的数据个数相等.但发送方和接收方之间的不同数据类型映射仍然是允许的.
此函数中的所有参数对根进程来说都是很重要的,而对于其他进程来说只有recvbuf、recvcount、recvtype、root和comm是必不可少的.参数root和comm在所有进程中都必须是一致的.
对数据个数和类型的描述不应当导致根进程消息缓冲区的任何部分被重读,这样的调用是错误的.
原则:尽管重读的限制是不必要的,但为与MPI_GATHER相对应,因此也加上了这个限制(原则结尾)
MPI_SCATTERV(sendbuf, sendcounts, displs, sendtype, recvbuf,
recvcount, recvtype, root, comm)
IN sendbuf 发送消息缓冲区的起始地址(可变)
IN sendcounts 整数数组(长度为组的大小),其值为发送到每个进程的数
据个数(整型)
IN displs 整数数组(长度为组的大小),每个入口i存放着相对于
sendbuf的位移,此位移处存放着从进程i中接收的输入数据
IN sendtype 发送消息缓冲区中元素类型(句柄)
OUT recvbuf 接收消息缓冲区的起始地址(可变)
IN recvcount 接收消息缓冲区中元素的个数(整型)
IN recvtype 接收消息缓冲区中元素的类型(句柄)
IN root 发送进程的序列号(句柄)
IN comm 通信子(句柄)
int MPI_Scatterv(void* sendbuf, int *sendcounts, int *displs,
MPI_Datatype sendtype, void* recvbuf, int recvcount,
MPI_Datatype recvtype, int root, MPI_Comm comm)
MPI_SCATTERV(SENDBUF, SENDCOUNTS, DISPLS, SENDTYPE, RECVBUF,
RECVCOUNT, RECVTYPE, ROOT, COMM, IERROR)
<type> SENDBUF(*), RECVBUF(*)
INTEGER SENDCOUNTS(*), DISPLS(*), SENDTYPE, RECVCOUNT, RECVTYPE,
ROOT, COMM, IERROR
MPI_SCATTERV是MPI_GATHERV的逆操作.
MPI_SCATTERV对MPI_SCATTER的功能进行了扩展,它允许向各个进程发送个数不等的数据,因为此时sendcounts是一个数组.同时还通过增加一个新的参数displs提供给用户更大的灵活性,使得可以将根进程的任意一部分数据发往其他进程.
MPI_SCATTERV的结果相当于根进程执行了n次发送操作:
MPI_Send(sendbuf+displs[i]*extent(sendtype),sendcounts[i],
sendtype,i,...),
然后每个进程执行一次接收操作:
MPI_Recv(recvbuf, recvcount, recvtype,i,...).
对于所有非根进程,发送消息缓冲区被忽略.
根进程中sendcount[i]和sendtype的类型必须和进程i的recvcount和recvtype的类型相同(但与各进程间的类型映射可以不同).这就意谓着在每个进程和根进程之间,发送的数据量必须和接收的数据量相等,但发送方和接收方之间的不同数据类型映射仍然是允许的.
此函数中的所有参数对根进程来说都是很重要的,而对于其他进程来说只有recvbuf、 recvcount、recvtype、root和comm是必不可少的.参数root和comm在所有进程中都必须是一致的.
对发送数据的个数、类型和偏移的设置不能引起根进程中的任何部分数据被重笔读取.
4.6.1 应用MPI_SCATTER和MPI_SCATTERV的例子
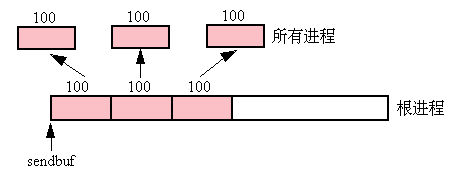
例4.11: 与例4.2相反,根进程将向组内的每个进程分散100个整型数据.见图4.7.
MPI_Comm comm;
int gsize,*sendbuf;
int root,rbuf[100];
......
MPI_Comm_size(comm, &gsize);
sendbuf = (int *)malloc(gsize*100*sizeof(int));
......
MPI_Scatter(sendbuf, 100, MPI_INT, rbuf, 100, MPI_INT, root, comm);
图4.7: 根进程向组内的所有进程分散100个整型数据
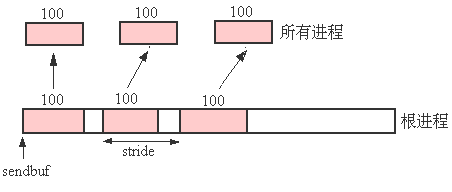
图4.8: 根进程分散100个整型数据,在分散时按步长stride取数据
例4.12: 与例4.5相反,根进程将向组内的每个进程分散100个整型数据, 但这每100个数据的集合在根进程的发送消息缓冲区中相隔一定的步长.见图4.8.
MPI_Comm comm;
int gsize,*sendbuf;
int root,rbuf[100],i,*displs,*scounts;
......
MPI_Comm_size(comm, &gsize);
sendbuf = (int *)malloc(gsize*stride*sizeof(int));
......
displs = (int *)malloc(gsize*sizeof(int));
scounts = (int *)malloc(gsize*sizeof(int));
for (i=0; i<gsize; ++i) {
displs[i] = i*stride;
scounts[i] = 100;
}
MPI_Scatterv(sendbuf, scounts, displs, MPI_INT, rbuf, 100,
MPI_INT, root, comm);
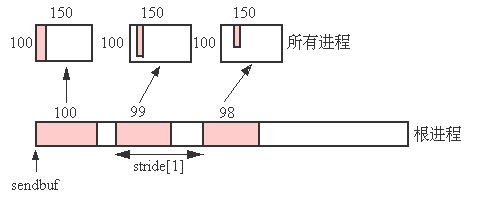
例4.13: 与例4.9相反,在发送端每个数据块之间的步长是一个变化的值,在接收端将其接收过来后存放在100*150数组中的第i列(以C语言为例).见图4.9.
MPI_Comm comm;
int gsize,recvarray[100][150],*rptr;
int root,*sendbuf,myrank,bufsize,*stride;
MPI_Datatype rtype;
int i,*displs,*scounts,offset;
......
MPI_Comm_size(comm, &gsize);
MPI_Comm_rank(comm, &myrank);
stride = (int *)malloc(gszie*sizeof(int));
......
/* stride[i]中存放着数据取自于发送消息缓冲区的地方,i从0到gsize-1 */
......
displs = (int *)malloc(gsize*sizeof(int));
scounts = (int *)malloc(gsize*sizeof(int));
offset = 0;
for (i=0; i<gsize; ++i) {
displs[i] = offset;
offset += stride[i];
scounts[i] = 100 - i;
}
/* 为接收的每一列生成相应的数据类型 */
MPI_Type_vector(100-myrank, 1, 150, MPI_INT, &rtype);
MPI_Type_commit(&rtype);
rptr = &recvarray[0][myrank];
MPI_Scatterv(sendbuf, scounts, displs, MPI_INT, rptr, 1, rtype,
root, comm);
图4.9: 根进程分散100*150数组的第i列中100-i个整型数据块.发送端的步长分别为stride[i]
| Copyright: NPACT |