F90中,允许把整个数组作为一个操作数进行操作,也允许在赋值语句中对整个数组进行赋值,就像对一个简单变量的操作和赋值一样。针对数组的特性,也有专门的运算方法和内在函数。
5.2.1
赋值
数组的赋值可以使用赋值语句和数组构造器。
F90中数组赋值语句的形式为:V=e,V代表数组名或数组片段,e为数组表达式,它们必须有相同的形状(即维数相同,每维长度相同但上下界可不同)。当V大小为0或为长度为0的字符型时,则没有值赋给V。当e为标量时,则把e处理成与V相同的形状,V的每个元素均等于标量e的值。数组表达式e中允许使用+、-、*、/、**等内部算术操作符。
F90允许赋值语句的表达式内只有标量,如A是![]() 数组,则A=3表示
数组,则A=3表示![]() 。例如,A(1:15)=2.0,则A(1)到A(15)的每个元素都被赋值为2.0。因此,数组赋值语句可以对整个数组一次赋值完毕,不必用DO构造对每一个元素逐一赋值,如对F77中的初始化置零DO循环:
。例如,A(1:15)=2.0,则A(1)到A(15)的每个元素都被赋值为2.0。因此,数组赋值语句可以对整个数组一次赋值完毕,不必用DO构造对每一个元素逐一赋值,如对F77中的初始化置零DO循环:
do i=1,10
do j=1,10
A(i,j)=0.
end do
end do
可以只要一个赋值语句A=0.就行。
例:A(
例:Q(
例:INTEGER A(20)
A(
数组构造器是由括号和斜线之间的一系列值或隐DO循环组成。其一般形式为:(/取值列表/)。取值列表可以是标量,隐DO循环或任意秩的数组。其中的所有值的类型都相同,以逗号隔开。如果列表中出现了数组,它的值是按列来赋的。
例:INTEGER A(6)
A=(/1,2,3,4,5,6/) !
斜杠与括号间不能有空格
例:C1=(/4,8,7,6/) !
标量表示
C2=(/B(I,1:5),B(I:J,7:9)/) !
数组表示
C3=(/(I,I=1,4)/) !
隐DO循环
C4=(/4,A(1:5),(I,I=1,4),7/) ! 混合表示
下面是一些数组构造器的替换格式:
1) 用方括号代替括号和斜线,例如下面两个数组构造器是等价的:
例:INTEGER C(4)
C=(/4,8,7,6/)
C=[4,8,7,6]
2) 冒号三元下标(代替隐DO循环)来指定值的范围和步长,例如下面两个数组构造器是等价的:
例:INTEGER D(3)
D=(/1:5:2/) !
三元下标格式
D=(/(I,I=1,5,2)/) ! 隐DO循环格式
由于计算机的内存是一维的,所以不管数组是几维,它在内存中都是按一维来存储的,数组的存储顺序对应于输入输出时给定数组元素数据的顺序。FORTRAN规定,一维数组在机内存贮时是按序存放的。而对二维数组,用第一个下标指明行序,第二个下标指明列序,则数组是按列存放的。即按序存放第一列内的诸元素,接着是第二列内诸元素,然后第三列、第四列直到最后一列。如A是![]() 数组,
数组,

则它在机内的存放顺序是A(1,1)->A(2,1)->A(3,1) => A(1,2)->A(2,2)->A(3,2) => A(1,3)->A(2,3)->A(3,3)。
高维数组的存放次序可由二维数组类推,即最右边指标(相当于最外层循环变量)变动最慢,最左边的第一个指标变动最快。
F90的赋值语句考虑到了在并行机上计算的功能,即使不是用的并行计算机,在形式上也是按并行化处理的。这与F77中的串行赋值是不同的,由此造成了数组的F90赋值结果与采用DO循环方式进行赋值的差异。
例:INTEGER :: a(0:9)=(/0,1,2,3,4,5,6,7,8,9/)
a(1:9)=a(0:8)
a的所有元素是并行处理的,结果是(/0,0,1,2,3,4,5,6,7,8/):
|a(0)|a(1)|a(2)|a(3)|a(4)|a(5)|a(6)|a(7)|a(8)|a(9)|
↑
↑ ↑ ↑
↑ ↑ ↑
↑ ↑
|a(0)|a(1)|a(2)|a(3)|a(4)|a(5)|a(6)|a(7)|a(8)|a(9)|
但是,如果用DO循环的话
DO i=1,9
a(i)=a(i-1)
END DO
A的元素是逐一处理的,结果是(/0,0,0,0,0,0,0,0,0/):
|a(0)|a(1)|a(2)|a(3)|a(4)|a(5)|a(6)|a(7)|a(8)|a(9)|
→
→ → →
→ → →
→ →
①
② ③ ④
⑤ ⑥ ⑦
⑧ ⑨
要用DO循环达到和上面同样的效果,需要数组的拷贝:
INTEGER :: a(0:9)=(/0,1,2,3,4,5,6,7,8,9/), b(0:9)
b=a
DO i=1,9
a(i)=b(i-1)
END DO
可以用内在函数RESHAPE语句把一个一维数组改变形状后赋给另一已知形状的数组。由于Fortran的数组顺序不同于C,Fortran中左边第一维是变化最快的,RESHAPE语句可以用于当Fortran过程化为C过程时将Fortran数组改序成C数组序。它的一般形式为:结果=RESHAPE(源,形状[,补充][,顺序])。源可以是任意数据类型的数组,它提供结果数组的元素。当补充被省略或其大小为0时,源的大小必须大于PRODUCT(形状)。形状为7个元素以下的一维固定的整型数组,它决定了结果数组的形状,其大小为正元素非负。补充为与源数组相同类型和属性的数组,当源数组的大小比结果数组小时用来补充元素值。顺序必须是和形状数组有相同形状的整型数组,其元素为(1,2,...,n)的排列,n是形状数组的大小。当顺序被省略时,默认值为(1,2,...,n)。
因此,结果数组的形状与形状数组相同,与源数组的类型和属性相同,大小是形状数组元素值的乘积。结果数组的元素是源数组的元素按顺序数组指定的维别顺序排列的,当省略顺序数组时元素按通常的顺序排列。源数组元素用完后按序用补充数组的元素,必要时重复使用补充数组直至结果数组的所有元素均有其值。
例:RESHAPE((/3,4,5,6,7,8/),(/2,3/))的结果是![]() 。
。
例:RESHAPE((/3,4,5,6,7,8/),(/2,4/),(/1,1/),(/2,1/))的结果是![]() 。
。
例:INTEGER AR1(2,5)
REAL F(5,3,8),C(8,3,5)
AR1=RESHAPE((/1,2,3,4,5,6/),(/2,5/),(/0,0/),(/2,1/))
! AR1的取值为 [1 2
3 4 5]
!
[6 0 0 0 0]
C=RESHAPE(F,(/8,3,5/),ORDER=(/3,2,1/)) ! 将Fortran数组序化为C数组序
END
例:INTEGER B(2,3),C(8)
B=RESHAPE((/1,2,3,4,5,6/),(/2,3/)) ! 赋值给形状为(2,3)的数组
C=(/O,RESHAPE(B,(/6/)),7/)
! 赋值给向量C之前先把B转换成向量
F90中提供了屏蔽数组赋值语句,它实质上是一种带条件的数组赋值语句,也就是说它只对某些符合条件的数组元素赋值。屏蔽数组赋值语句,为WHERE语句和WHERE构造,其形式非常类似于逻辑IF语句和IF构造。
WHERE语句的一般形式为:WHERE(屏蔽表达式) 赋值语句
WHERE构造的一般形式为:
[构造名:]
WHERE(屏蔽表达式1)
[块]
[ELSEWHERE(屏蔽表达式2) [构造名]
[块]]
[ELSEWHERE [构造名]
[块]]
END WHERE [构造名]
其中屏蔽表达式都是数组逻辑表达式。这里要求数组赋值语句中被定义的变量和屏蔽表达式必须都是数组,且形状相同,而且数组赋值语句不能是自定义的赋值语句。
在执行WHERE语句时,当数组逻辑表达式的某个数组元素的值为.TRUE.时,才对赋值语句表达式的相应元素求值,赋给被定义的数组元素。同样,在执行WHERE构造时,逻辑表达式的取值结果(数组元素)为.TRUE.时,执行屏蔽表达式后面的块;而元素值为.FALSE.时,执行ELSEWHERE后面的块。注意与IF构造不同的是,这里没有关键字THEN和ELSE块。
例如,要对数组A中绝对值大于1的元素取倒数,其余的元素值不变,其语句为:WHERE(ABS(A)>1.0) A=1./A。如果同时还要记录哪些元素作了变换,可用数组B记录变换情况,语句为:
B=.FALSE.
WHERE(ABS(A)>1.0) B=.TRUE.
WHERE(ABS(A)>1.0) A=1./A
显然,上面最后一行可以写成:WHERE(B) A=1./A
若采用WHERE构造,上例可改写为:
B=.FALSE.
WHERE(ABS(A)>1.0)
B=.TRUE.
A=1./A
END WHERE
这样改写后可以提高程序的执行效率。当然,还可以改写成下面的等价形式:
WHERE(ABS(A)>1.0)
B=.TRUE.
A=1./A
ELSEWHERE
B=.FALSE.
END WHERE
例:INTEGER A,B,C
DIMENSION A(5),B(5),C(5)
DATA A/0,1,1,1,0/
DATA B/10,11,12,13,14/
C=-1
WHERE(A.NE.0) C=B/A
则数组C的元素为(-1,11,12,13,-1)。
FORALL是F95的新增功能。它是数组屏蔽赋值(WHERE语句和构造)功能的一对一元素的推广,其方式有FORALL语句和FORALL构造。
FORALL语句的一般形式为:FORALL(循环三元下标[,循环三元下标]…[,屏蔽表达式]) 赋值语句
FORALL构造的一般形式为:
[构造名:]
FORALL(循环三元下标[,循环三元下标]…[,屏蔽表达式])
[块]
END FORALL [构造名]
屏蔽表达式是数组逻辑表达式,缺省值为.TRUE.。块是赋值语句,或为WHERE语句或构造,或为FORALL语句或构造。
循环三元下标的形式为:循环变量=下界:上界[:步长]。循环变量是整型的。步长不能为0,缺省值为1。
例:INTEGER :: mat(0:7,0:7)
FORALL(i=0:7,j=0:7) mat(i,j)=8*i+j
它等价于
FORALL(i=0:7,j=0:7)
mat(i,j)=8*i+j
END FORALL
如果要用F77的语句写出来的话,则为
DO i=0,7
DO j=0,7
mat(i,j)=8*i+j
END DO
END DO
例:REAL :: a(0:n)
WHERE(a>0.0) a=SQRT(a)
等价于
FORALL(i=0:n,a(i)>0.0) a(i)=SQRT(a(i))
例:WHERE(A/=0.) B=1./A
等价于
FORALL(I=1:N,J=1:N,A(I,J).NE.0.) B(I,J)=1./A(I,J)
等价于
FORALL (I=1:N,J=1:N)
IF(A(I,J).NE.0.) B(I,J)=1./A(I,J)
END FORALL
例:INTEGER :: num(0:7)=(/0,1,2,3,4,5,6,7/)
FORALL(i=1:7) num(i)=num(i-1)
等价于
FORALL(i=1:7)
num(i)=num(i-1)
END FORALL
等价于
a(1:7)=a(0:6)
不等价于
DO i=1,7
num(i)=num(i-1)
END DO
[e_521_01.f90]
5.2.2
运算
允许把整个数组或数组片段作为一个单独的对象进行运算。例如当数组A,B,C有相同大小和形状时,C=A+B语句实现对数组所有元素的并行加法运算。所有的算术运算符(+,-,*,/,**)、逻辑运算符(如.AND.,.OR.,.NOT.)和所有关系运算符(如.LT.,.EQ.,.GT.),还有很多内在函数都可以接受数组名称作为参数并对数组元素逐一运算。
例:INTEGER, DIMENSION(100)::
even,odd,plu,min,tim,div,squ
even=(/(2*i,i=0,49)/); odd=(/(2*i+1,i=0,49)/)
plu=even+odd
min=even-odd
tim=even*odd
div=even/odd
squ=even**2
可以使用数组名作为参数的内在函数称为基本内在函数。
例:REAL A(5),B(5),C(5)
INTEGER D(5)
DATA PI/3.14159265/
A=(/(REAL(I)*PI/180.,I=1,5)/)
B=COS(A); C=SQRT(A); D=CEILING(A*180.)
其中COS,SQRT和CEILING都是基本内在函数。当两个以上数组出现在赋值语句或表达式中时,数组的形状应该相同(称为相容)。例如数组A(2,3),B(2,3),C(2:3,6:8)都是相容的,而数组D(4,5),E(5,4),F(5,2,2)都是不相容的。
例:X(
如果数组片段指定的部分相容,则它也可以用于表达式和赋值。这样,不相容的数组也可以互相使用。例如,一个较小的完整数组可以和一个相容的大数组的片段进行运算:
例:REAL A(5),B(4,7)
A=20.; B=5.; A=A-B(2,1:5)
两个数组作算术操作的结果仍是一个形状相同的数组,它的每个位置上元素的值是参与操作的相同位置上一对元素操作后的结果值。例如有数组A、数组B,形状如下:
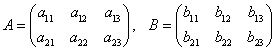 ,
,
则执行赋值语句C=A+B后,数组C的值即为
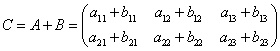 。
。
对于其它内部操作,如+、-、*、/、**等,操作结果也是一个形状相同的数组。它的每个位置上的元素值是参与操作的数组相同位置上的一对元素(不管它们的下标是否相同)作相同操作的结果。
数组表达式允许数组与标量作算术运算。当A、B为形状相同的数组时,赋值语句A=B+2是合法的。表达式是数组B与标量值2相加,这时可以把标量看作形状与B相同的数组,其每一元素的值都是2,而后与B数组和加,其结果为:
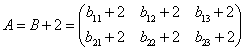 ,
,
也即数组与标量操作相当于数组内每一元素与该标量操作。
数组表达式中允许对数组求基本函数,其函数值仍是一个形状相同的数组,它的每个位置上的元素值就是被操作数组对应位置元素取该函数值,例如A、B为形状相同的一维数组,则语句B=SQRT(A)表示:B(1)=SQRT(A(1))、B(2)=SQRT(A(2)),…。
F90中增加了许多新的数组专用内在函数,使得数组的运算更加灵活方便。下面是一部分新增的数组内在函数。
![]() 矩阵乘积函数:MATMUL(A,B)
矩阵乘积函数:MATMUL(A,B)
描述:执行数值或逻辑型矩阵A与B的矩阵乘法。
说明:矩阵A和B必须是秩为1或2的数值型或逻辑型的有值数组,且A与B的类型必须相同,A,B中至少有一个秩是2。A与B的矩阵乘积规则和结果值与数学上的定义相同,A的最后一维的长度必须和B的第一维的长度相同。
![]() 向量点乘函数:DOT_PRODUCT(A,B)
向量点乘函数:DOT_PRODUCT(A,B)
描述:执行数值或逻辑型向量A与B的点积乘法。
说明:向量A和B必须是秩为1(即向量)的数值型或逻辑型的有值数组,且A与B的类型必须相同。向量A与B点乘的结果是标量,其规则和结果值与数学上的定义相同。
例:DOT_PRODUCT((/1,2,3/),(/2,3,4/))的值为20。
![]() 数组归约函数:包括SUM、PR0DUCT、MAXVAL、MINVAL、COUNT、ANY和ALL函数。
数组归约函数:包括SUM、PR0DUCT、MAXVAL、MINVAL、COUNT、ANY和ALL函数。
★ 元素求和函数:SUM(ARRAY[,DIM][,MASK])
描述:沿着维DIM,对在MASK真值中的数组ARRAY的所有元素求和。
说明:ARRAY是被求和的数组名。DIM用于指明选哪一维来求函数值。当“DIM=1”时分别按列求和,“DIM=2”时分别按行求和。MASK是屏蔽表达式,不满足条件的元素则被屏蔽,不参加求函数值。
例:SUM((/4,5,6/))的值是15。
例:SUM(C,MASK=C>0.0)是对C的所有正元素值的求和。
例:若![]() ,则SUM(A,DIM=1)的值是[3,5,7],SUM(A,DIM=2)的值是[9,6]。
,则SUM(A,DIM=1)的值是[3,5,7],SUM(A,DIM=2)的值是[9,6]。
★ 元素连乘求积函数:PRODUCT(ARRAY[,DIM][,MASK])
描述:沿着维DIM,对在MASK真值中的数组ARRAY的所有元素求连乘积。
例:PRODUCT((/4,5,6/))的值是120。
例:PRODUCT(C,MASK=C>0.0)是对C的所有正元素值的求连乘积。
例:若![]() ,则PRODUCT(A,DIM=1)的值是[2,6,12],SUM(A,DIM=2)的值是[24,6]。
,则PRODUCT(A,DIM=1)的值是[2,6,12],SUM(A,DIM=2)的值是[24,6]。
![]() 数组查询函数:包括SIZE、SHAPE、ALLOCATED、LBOUND和UBOUND函数。
数组查询函数:包括SIZE、SHAPE、ALLOCATED、LBOUND和UBOUND函数。
★ 求数组大小函数:SIZE(ARRAY[,DIM])
描述:求数组ARRAY沿着维DIM的长度或数组元素的总数目。
★ 求数组形状函数:SHAPE(ARRAY)。
描述:求数组或标量的形状。
![]() 数组的构造函数:包括MERGE、PACK,UNPACK和SPREAD函数。
数组的构造函数:包括MERGE、PACK,UNPACK和SPREAD函数。
描述:数组构造函数用于从已有数组的元素构造出新数组。
★ 合并数组函数:MERGE(TSOURCE,FSOURCE,MASK)
描述:在MASK的控制下,合并数组TSOURCE和FSOURCE。
说明:数组TSOURCE可以是任一类型,数组FSOURCE必须与TSOURCE具有相同的类型和类型参数。MASK必须是逻辑型数组。若MASK为真,则结果是TSOURCE,若为假,则结果是FSOURCE。
例:MERGE(1.,0.,R<0)的结果是:当R=-2,取值为1.0;当R=2,取值为0.0。
例:若![]() ,
,![]() ,
,![]() ,则MERGE(A,B,M)=
,则MERGE(A,B,M)=![]() 。
。
★ 压缩数组函数:PACK(ARRAY,MASK[,VECTOR])
描述:在MASK控制下,将数组ARRAY压缩成向量数组。
说明:ARRAY可是任意类型的数组。MASK必须是逻辑型数组并与ARRAY相容。VECTOR(可选)必须为向量数组,且与ARRAY具有相同的类型和类型参数。结果是秩为1的数组,其类型和类型参数与ARRAY相同;若VECTOR存在,结果大小等于VECTOR的大小,否则其大小是MASK中真元素的个数t,若MASK为标量且为真值,这时结果的大小与ARRAY相同。结果的值按数组中元素排序,ARRAY中的第i个元素对应于MASK的第i个真元素。若VECTOR存在,且大小n>t,则结果中第i个元素值为VECTOR(i),i=t+1,…,n。
例:若 ,其非0元素可由PACK函数收集,PACK(A,MASK=A.NE.0)的结果为[9,7],PACK(A,A.NE.0,VECTOR=(/1,2,3,4,5,6/))的结果值为[9,7,3,4,5,6]。
,其非0元素可由PACK函数收集,PACK(A,MASK=A.NE.0)的结果为[9,7],PACK(A,A.NE.0,VECTOR=(/1,2,3,4,5,6/))的结果值为[9,7,3,4,5,6]。
★ 拷贝数组函数:SPREAD(SOURCE,DIM,NCOPIES)
描述:将数组SOURCE沿着DIM方向拷贝NCOPIES次后扩展成一新的数组。
说明:当DIM=1时,即沿着第一维下标变化的方向扩展,也即向下扩展。DIM=2时,沿着第二维下标变化方向扩展即向右扩展。
例:若 ,片段
A(2,2:4)=[2.2,2.3,2.4],
,片段
A(2,2:4)=[2.2,2.3,2.4],
则SPREAD(A(2,2:4),1,3)为 ,SPREAD(A(1:3,1),2,3)为
,SPREAD(A(1:3,1),2,3)为 。
。
例:SPREAD("B",1,4)为数组(/"B","B","B","B"/)。
![]() 数组重构形函数:RESHAPE(SOURCE,SHAPE[,PAD][,ORDER])
数组重构形函数:RESHAPE(SOURCE,SHAPE[,PAD][,ORDER])
![]() 数组运算函数:包括TRANSPOSE、EOSHIFT和CSHIFT三个函数。
数组运算函数:包括TRANSPOSE、EOSHIFT和CSHIFT三个函数。
★ 矩阵转置函数:TRANSPOSE(MATRIX)
描述:将秩为2的数组转置。
例:若A是数组![]() ,则TRANSPOSE(A)为
,则TRANSPOSE(A)为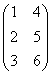
★ 去端移动函数:EOSHIFT(ARRAY,SHIFT[,BOUNDARY][,DIM])
描述:对秩为1的数组表达式作去端移位,或沿着维DIM对秩为>1的数组表达式在所有秩为1的完整数组片段上作去端移位。在一个数组片段的一端被移出的元素被丢弃,并在另一端移入相同的BOUNDARY的值。不同的片段可以有不同的BOUNDARY值,并可在不同的方向上移动不同的位数。SHIFT为正值去端左移,为负值去端右移。
例:若A是数组[2,4,6,8,10],则EOSHIFT(A,SHIFT=3)去端左移3位的结果是[8,10,0,0,0];而用EOSHIFT(A,SHIFT=-2,BOUNDARY=36)去端右移2位的结果为[36,36,2,4,6]。
一个秩为2的数组的各行可以移动相同或不同数量的元素,边界元素也可以相同或不同。
例:若B是数组 ,
,
则EOSHIFT(B,SHIFT=1,BOUNDARY='*',DIM=2)为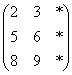 ,EOSHIFT(B,SHIFT=-1,DIM=1)为
,EOSHIFT(B,SHIFT=-1,DIM=1)为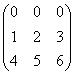
EOSHIFT(B,SHIFT=(/1,-1,0/),BOUNDARY=(/'*','?','/'/),DIM=2)为
★ 循环替换函数:CSHIFT(ARRAY,SHIFT[,DIM])
描述:将秩为1的数组的所有元素或高维数组的指定维上的元素进行循环移动。在一端上移走的元素被插到另一端。SHIFT=正值时被移向左端,负值移向右端。
例:若A是数组[1,2,3,4,5,6],则CSHIFT(A,SHIFT=2)是[3,4,5,6,1,2];而用CSHIFT(A,SHIFT=-2)是[5,6,1,2,3,4]。
![]() 数组定位函数:有MAXLOC和MINLOC两个函数。
数组定位函数:有MAXLOC和MINLOC两个函数。
★ 最大值元素定位函数:MAXLOC(ARRAY[,DIM][,MASK])
描述:根据MASK的真值条件确定ARRAY的所有元素中或沿维DIM中第一个最大值元素出现的位置。
例:MAXLOC(/3,8,5,8/)的值为[2]。
例:若A是数组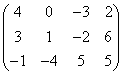 ,则MAXLOC(A,MASK=A.LT.5)为[1,1],MAXLOC(A,DIM=1)为[1,2,3,2],MAXLOC(A,DIM=2)为[1,4,3]。
,则MAXLOC(A,MASK=A.LT.5)为[1,1],MAXLOC(A,DIM=1)为[1,2,3,2],MAXLOC(A,DIM=2)为[1,4,3]。
要注意的是,表达式中数组进行操作后,不再保留原来的下标形式,由系统将它们按线下界为1重新排列。这样,参与操作的两个数组原来的下标是否相同,可以不必考虑。但在引用某些与下标有关的函数时.要记住此时的函数值以整理过的新下标值出现。例如定义一个数组A及其初值如下:
INTEGER, DIMENSION(0:6),PARAMETER :: A=(/3,7,0,-2,3,6,-1/)
因值7是A中元素的最大值,元素的下标是A(1),即数组A中最大值元素的下标为1。但内部函数MAXLOC的返回值是2而不是1,即返回的不是原来的下标值,而是以1为维下界整理过的下标值。
F90数组运算内在函数表
|
函数名称 |
描述 |
|
ALL(mask[,dim]) |
判断全部数组值在指定维上是否都满足mask的条件 |
|
ANY(mask[,dim]) |
判断是否有数组值在指定维上满足mask的条件 |
|
COUNT(mask[,dim]) |
统计在指定维上满足mask的条件的元素个数 |
|
CSHIFT(array,shift[,dim]) |
进行指定维上的循环替换 |
|
DOT_PRODUCT(vector_a,vector_b) |
进行两个向量的点乘 |
|
EOSHIFT(array,shift[,boundary][,dim]) |
在指定维上替换掉数组末端,复制边界值到数组末尾 |
|
LBOUND(array[,dim]) |
返回指定维上的下界 |
|
MATMUL(matrix_a,matrix_b) |
进行两个矩阵(二维数组)的乘积 |
|
MAXLOC(array[,dim][,mask]) |
返回数组的全部元素或指定维元素当满足mask条件的最大值的位置 |
|
MAXVAL(array[,dim][,mask]) |
返回在指定维上满足mask条件的最大值 |
|
MERGE(tsource,fsource,mask) |
按mask条件组合两个数组 |
|
MINLOC(array[,dim][,mask]) |
返回数组的全部元素或指定维元素当满足mask条件的最小值的位置 |
|
MINVAL(array[,dim][,mask]) |
返回在指定维上满足mask条件的最小值 |
|
PACK(array,mask[,vector]) |
使用mask条件把一个数组压缩至vector大小的向量 |
|
PRODUCT(array[,dim][,mask]) |
返回在指定维上满足mask条件的元素的乘积 |
|
RESHAPE(source,shape[,pad][,order]) |
使用顺序order和补充pad数组元素来改变数组形状 |
|
SHAPE(source) |
返回数组的形状 |
|
SIZE(array[,dim]) |
返回数组在指定维上的长度 |
|
SPREAD(source,dim,ncopies) |
通过增加一维来复制数组 |
|
SUM(array[,dim][,mask]) |
返回在指定维上满足mask条件的元素的和 |
|
TRANSPOSE(matrix) |
转置二维数组 |
|
UBOUND(array[,dim]) |
返回指定维上的上界 |
|
UNPACK(vector,mask,field) |
把向量在mask条件下填充field的元素解压至数组 |
数组的输入输出可以用隐DO循环指定每维循环变量,也可单给出数组名、数组元素或数组片段。
![]() 一维数组:
一维数组:
一维数组的输入输出比较简单,它在机内存贮时作线性排列,依次读入(输出)的数逐一按下标值递增赋给(打印)各元素:
例:INTEGER :: a(10)
READ *, (a(i), i=1,10) ← 可以1行输入10个值,也可输入1个值(隐DO循环)
READ *, a ← 同上
(数组名)
DO i=1,10
READ *,a(i) ← 1行只能输入1个值,输入2个以上被忽略
END DO
READ *, a(3),a(4:6) ← 输入数组元素和数组片段:a(3),a(4),a(5),a(6)
PRINT '(10I5)',(a(i),i=1,10) ← 1行打印10个值 (隐DO循环)
PRINT '(10I5)',a ← 同上
(数组名)
PRINT '(5I5)',a(1:5) ← 1行打印5个值 (数组片段)
DO i=1,10
PRINT '(I5)',a(i) ← 1行打印1个值,共打10行
END DO
![]() 二维数组:
二维数组:
二维数组的输入输出读写语句使用与一维情况时一样,数组元素输入输出的顺序是按前面提到的数组的存储顺序来进行的。由于二维数组的顺序是首先按列存放,因此对于输入![]() 数组的A,执行语句READ *,A时,则读入数据的顺序是A(1,1)->A(2,1)->A(3,1) => A(1,2)->A(2,2)->A(3,2)
=> A(1,3)->A(2,3)->A(3,3)。按列存贮方式与我们数学上按行处理的习惯不一致,在给数组各元素赋值时,先输入第一列元素的值,再输入第二、第三列的值这样机内收到的矩阵才是正确的。
数组的A,执行语句READ *,A时,则读入数据的顺序是A(1,1)->A(2,1)->A(3,1) => A(1,2)->A(2,2)->A(3,2)
=> A(1,3)->A(2,3)->A(3,3)。按列存贮方式与我们数学上按行处理的习惯不一致,在给数组各元素赋值时,先输入第一列元素的值,再输入第二、第三列的值这样机内收到的矩阵才是正确的。
如一定要按行方式输入矩阵值,可以通过交换隐DO循环内外层循环变量的方法来实现。如READ *,A与READ *,((A(I,J),I=1,3),J=1,3)是等价的,交换内外层循环变量后:READ *,((A(J,I),I=1,3),J=1,3)或READ *,((A(I,J),J=1,3),I=1,3),这时输入顺序是按行的:A(1,1)->A(1,2)->A(1,3) => A(2,1)->A(2,2)->A(2,3) => A(3,1)->A(3,2)->A(3,3)。
5.2.3
数组的动态分配
数组可以是静态的也可以是动态的。如果数组是静态的,则在编译时就被分配了固定的储存空间,并且直到程序退出时才被释放。程序运行时静态数组的大小不能改变。静态数组的缺陷是,即使数组已经使用完毕,它仍占据着内存空间,浪费了系统资源。在给定的计算机内存资源情况下,耗费了其他数组可以利用的内存,并且超过资源的数组将导致程序执行错误。因此,F90增加了动态的数组功能,动态数组的储存在程序运行当中是可以分配、改变和释放的。
动态数组只有两种:可分配数组和自动数组。自动数组和可分配数组很类似,区别在于当程序开始或结束时,自动数组会自动分配和释放内存。当用户分配动态存储空间时,数组的大小是在运行时而不是在编译时确定的。动态分配可以用于标量和任何类型的数组。当用户给数组指定了可分配属性时并没有立即分配内存,而是直到使用ALLOCATE语句后才分配。随后还可以用DEALLOCATE语句释放内存空间,这时数组可以以其它形状或目的来使用。
应该注意的是,WinNT/9x上运行的Visual Fortran动态内存分配受一些因素的限制,包括交换文件的大小和其它同时运行的应用程序所需的内存大小。如果动态分配的内存太大或试图使用其它应用程序的保护内存会产生一般内存保护错误。碰到这类问题可以通过控制面板来改变虚拟内存的大小或交换文件的大小,还有一些编程技术可以降低内存需要。
ALLOCATE语句动态创建可分配数组,使内存和对象相联系。分配的对象可以被命名为任何有ALLOCATABLE属性的变量。它的一般形式为:
ALLOCATE(数组名[维界符][,数组名[(维界符[,维界符...])]
] ...[,STAT=状态值])。
例:REAL A(:),B(:,:,:)
ALLOCATABLE A,B
ALLOCATE(A(-
当数组被分配时,内存分配给指定大小的数组。ALLOCATE语句中的秩必须和可分配数组的秩相同。在分配的同时,ALLOCATE语句中的上下界决定了数组的大小和形状。边界的值可以是正数、负数或零,缺省的下界为1。如果维上界比下界小,则该维的长度为零,并且数组的大小为零。大小为零的数组不能被赋值。
当前被分配的数组不能被再分配,否则会引起运行错误。错误状态可以由ALLOCATE语句中的STAT值获得。如果指定STAT选项,语句的成功执行时将返回0,否则返回正值。若未指定STAT选项且出现错误时,程序将中止执行。
例:INTEGER, ALLOCATABLE :: A(:),B(:)
INTEGER ERR_MESSAGE
ALLOCATE(A(
IF(ERR_MESSAGE.NE.0) PRINT *,'ALLOCATION ERROR'
可以用内在函数ALLOCATED来判断一个数组是否已被分配。它的形式为:ALLOCATED(数组名)。返回值是逻辑标量,已被分配时为真,现在还未被分配时为假,当数组的分配状态未定义时它也是未定义的。
例:REAL, ALLOCATABLE :: A(:)
...
IF(.NOT.ALLOCATED(A)) ALLOCATE(A(5))
DEALLOCATE语句用来释放已分配数组的内存。它的一般形式为:DEALLOCATE(数组名[,数组名]...[,STAT=状态值])。
例:INTEGER, ALLOCATABLE :: A(:),B(:)
INTEGER ERR_MESSAGE
ALLOCATE(A(
DEALLOCATE(A,B,STAT=ERR_MESSAGE)
IF(ERR_MESSAGE.NE.0) PRINT *,'DEALLOCATION ERROR'
例:INTEGER,DIMENSION(:),ALLOCATABLE :: freq
READ *,limit
ALLOCATE(freq(1:limit))
DEALLOCATE(freq)
只有被ALLOCATE语句分配的内存空间才可以被DEALLOCATE语句释放,否则产生运行错误。可以使用ALLOCATED语句判断数组是否被分配,错误状态可以由ALLOCATE语句中的STAT值获得。
当过程的执行被RETURN或END语句中止时,除非可分配数组是有SAVE属性的,否则它的分配状态变成未定义的。但是,RETURN和END语句并不释放数组分配的内存,所以应该在退出子程序前主动释放数组分配的内存。
可分配数组的联合状态可以是已分配的(该数组被ALLOCATE语句分配,可以被引用、定义或释放)或是目前未联合(该数组从未分配或上一个操作是释放,数组不能被引用或定义)。
当可分配数组赋值时就被定义。
例:INTEGER, ALLOCATABLE :: A(:)
ALLOCATE(A(100)) !
A被分配但未定义,A的分配状态是己分配
A(1:100)=1 !
A被定义
DEALLOCATE(A) ! A被释放,A的分配状态是未分配
【作业】
[5.1] 用类型说明语句定义:
(1) 一个整型数组,10个元素,名I;
(2) 一个逻辑型数组,2维,第一维维界是0:7,第2维维界是-7:0,名L;
(3) 一个字符型数组,1维,下标从1变到100,名C;
(4) 把矩阵![]() 定义成数组,名R;
定义成数组,名R;
[5.2]
设数组![]() ,
,![]() ,
,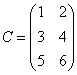 ,
,![]() ,E数组描述为(1:2,1:3),F数组描述为(1:3),问下列数组表达式是否合法,不合法的说明理由,合法的写出计算结果:
,E数组描述为(1:2,1:3),F数组描述为(1:3),问下列数组表达式是否合法,不合法的说明理由,合法的写出计算结果:
(1) E=A+B
(2) E=ABS(B)+2
(3) E=B+C
(4) C=A+C
(5) F=D*D
(6)
F=A(1:2,1)+B(1:3,1)
(7)
F=A(1,1:3)+B(1,1:3)
[5.3] 用WHERE构造,使上题中A元素≤2时,置B相应元素为自身的绝对值,否则使B中元素加1,写出最后B的内容。
[5.4] 读入一个二维数组A,形状为(1:5,1:3),任意输入具体数据。
(1) 用DO循环求全部数组元素和,再用数组内部专用求和函数求和,比较两者结果。
(2) 用DO循环求数组元素连乘积,再用数组内部求连乘积函数求整个数组元素之积,比较两者结果。
[5.5] 用动态数组存放任意读入的N个储款数,统计这次存款总数,而后释放数组,再把它存贮任意读入的M个取款数,统计共被取出的款额,求收支相抵的余额。